


 閉じる
閉じる
知能と研究開発の最前線
米国発「身体化AI」実装への挑戦(1)
2026年2月26日
生成人工知能(AI)の物理空間への拡張の試みとして、ロボットを対象とする身体化AI(Embodied AI)への関心が高まっている。世界のヒューマノイド・スタートアップへの投資額は2023年の3億6,000ドルから2024年には11億9,000万ドルへと急拡大した(図参照)。こうした潮流の中で、2025年12月にカリフォルニア州シリコンバレーで開催された「ヒューマノイド・サミット![]() 」(2025年12月19日付ビジネス短信参照)は、大規模言語モデル(LLM)中心のAIカンファレンスとは一線を画し、ロボットという「身体」へのAIの実装と商業化を議論する場として注目を集めた。本稿では、米国でのヒューマノイド・エコシステムについて、サミット全体の議論から、最新技術や産業動向を整理する。
」(2025年12月19日付ビジネス短信参照)は、大規模言語モデル(LLM)中心のAIカンファレンスとは一線を画し、ロボットという「身体」へのAIの実装と商業化を議論する場として注目を集めた。本稿では、米国でのヒューマノイド・エコシステムについて、サミット全体の議論から、最新技術や産業動向を整理する。
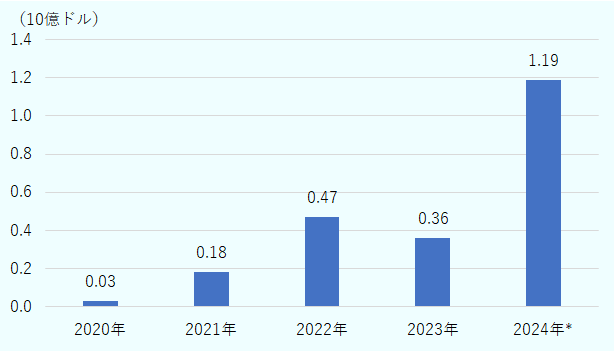
注:2024年は速報値。
出所:Accenture. "Total funding of humanoid robot startups globally from 2020 to 2024, in billion U.S. dollars.![]() " Chart. January 6, 2025. Statista. Accessed December 18, 2025.からジェトロ作成
" Chart. January 6, 2025. Statista. Accessed December 18, 2025.からジェトロ作成
ヒューマノイド知能はどこへ向かうのか、世界モデルとVLA
サミット全体を通じて登壇者の多くが言及したキーワードの1つが「世界モデル(ワールド・モデル)」だ(注1)(2025年11月25日付ビジネス短信参照)。「世界モデル」とは、ロボットが現実空間の構造や因果関係を内部モデルとして保持し、行動の結果を仮想的にシミュレーションすることで、より適切な行動を選択する枠組みを指す。パネルディスカッションでは、「世界モデル」は1つの完成した「正解のモデル」を指すのではなく、物理的法則や環境の不確実性をどの程度の精度で、どこまでロボットの内部に取り込むかという「設計の考え方」だとの認識が共有された。
一方、実装面で中心的な役割を担うのがVLA(Vision Language Action)(注2)モデルだ。VLAは視覚・言語・行動を統合し、ロボットの意思決定から実行まで統合的に扱うアーキテクチャーの1つで、グーグルのジェミニ・ロボティクスや複数のスタートアップがこの枠組みを採用している。サミットでは、世界モデルが「何を理解させたいか」という枠組みであるのに対し、VLAはそれをロボット上で動かすための現実的な命令セットだと紹介された。例えば、VLAでは「リンゴを掴め」といった言語指示を、具体的な「モーターの回転角」や「座標」といったトークン(注3)に変換するという。
身体化AIを支える学習データ戦略
身体化AIの開発で、データが大きな制約条件になっているという指摘が多く挙がった。言語モデルがインターネット上の膨大なテキストを活用できたのに対し、身体化AIには同等の「公共で入手可能なデータ」が存在しない。このため実世界データ、合成データ、テレオペレーションデータをどう組み合わせるかも重大な論点として挙げられた。
実世界データは信頼性が高い一方、収集コストが高く、スケールにも限界がある。これを補完する手段として、シミュレーションを用いた合成データの有効性が指摘された。特に学習初期や一般的な能力の向上に合成データは不可欠とされる。一方、テレオペレーションは現実世界の多様性を取り込みつつ、段階的に自律度を高めるための現実的な手段として位置付けられていた。全体としては、万能なデータ源は存在せず、開発フェーズに応じた使い分けが必要とされた。
人間らしい動きを阻むデクステリティと触覚の壁
登壇者から技術的な課題として繰り返し指摘されたのが、デクステリティ〔器用さ、巧緻(こうち)性〕(注4)と触覚、および全身運動制御などの技術的課題だ(2025年11月17日付ビジネス短信参照)。ナプキンや洗濯物を畳むこと、変形物の操作、両手協調などは産業ロボットが苦手としてきた領域だ。セッションではハードウエアの視点からではなく、継続的な学習を用いることで、信頼度の高い操作事例が示された。また物理シミュレーションを繰り返し行うことで、短期間で能力向上を示した事例も紹介された。
ハードウエアの低コスト化と進む量産化
今回のサミットで特徴的だったのは、ハードウエアの進展が前提として扱われていた点だ。アクチュエータ(注5)やセンサー、制御系の性能向上に加え、生産規模の拡大によるコスト低下により、研究用途に限られていたヒューマノイドについて、一部のスタートアップでは実験と実証を高速に回せる環境が整い始めている。特に中国企業の量産力によって、ロボットが安価に入手できることから、複数のスタートアップが中国企業のロボットを使用し、ロボットの頭脳に相当するAIモデルの開発競争を加速させている。

完全汎用化を待たない、用途特化型ヒューマノイドが現実的な選択肢か
セッションを通じて浮かび上がったのは、完全な汎用(はんよう)ヒューマノイドの実現は中・長期の課題と捉えられ、短期的には用途特化型の展開が現実的な選択肢だという認識だ。倉庫、工場、点検、サービスなど用途に特化した環境で、ヒューマノイドの導入が先行している。
今回のサミットを通じ、ハードウエアの性能向上やコスト低下によって、開発の重点がAIモデルやデータ基盤の安全性へ向かいつつあり、政策支援を伴う重層的なエコシステムの形成が始まったことが伺える。登壇者からヒューマノイドは製品というよりは、プラットフォームとして捉える見方も共有され、今後はソフトウエアやAIモデルを軸にした陣営形成が進むとの見方が示された。
地域別に見ると、米国ではシリコンバレーを中心に、基盤モデルやソフトウエア主導で汎用性を追求する動きが強く、大学やスタートアップ、大手テック企業の連携を通じた長期的な技術蓄積が進んでいるとの見方が示された。一方、中国では政府の手厚い支援のもと、特定用途での早期実装と量産を重視した垂直統合型エコシステムが形成されつつあり、実証から商用化までのスピードが強みとの指摘もあった。
日本からは、AIモデルやデータ基盤を含めた横断的なエコシステム構築を目指すAIRoA(AIロボット協会)が登壇し、製造現場で培われた高い信頼性、安全性、精密制御技術を紹介したほか、国際標準化やスタートアップとの協業の重要性が強調された(2025年12月19日付ビジネス短信参照)。
- 注1:
-
ヤン・ルカン氏らが提唱する次世代AIの概念。従来のAI(LLM)に欠けていた「物理的な常識」を学習させることで、AIが物理世界の仕組みを内部でシミュレーションし、「次に何が起こるか」を予測する機能を指す。ヒューマノイドが複雑な現実環境で自律的に動くための鍵として注目されている。

- 注2:
-
視覚(Vision)と言語(Language)の理解に、具体的な動作(Action)を統合したAIモデル。従来のAI(LLM)では、「画像を見て説明する」だけだったのに対し、VLAでは「画像と指示を理解し、実際にロボットを動かす」までを一気に行う。
- 注3:
-
AIが情報を処理する際に扱う最小単位のデータ。最新のVLAモデルでは、動作も言語と同じようにトークンへと数値化して処理する。
- 注4:
-
ロボットが対象物の形状、硬さ、摩擦などを瞬時に判断し、指先を細かく制御して複雑な操作を行う能力。現在、触覚センサーとAI(VLA等)の融合により、この能力の向上が図られている。
- 注5:
-
電気や空気、油圧などのエネルギーを使って、ロボットや機械を実際に動かす装置。
米国発「身体化AI」実装への挑戦
シリーズの次の記事も読む

- 執筆者紹介
-
ジェトロ・サンフランシスコ事務所
松井 美樹(まつい みき) - オーストラリア国立大学PhD、カーネギーメロン大学ポスドクフェローなどを経て、シリコンバレーで半導体・AI分野の産業分析に従事。応用計量経済学が専門。2023年11月末から現職。
よく見られているレポート
- EUの包装・包装廃棄物規則(PPWR)は不確定事項が山積 (2026年03月31日)
- 中国のレアアース輸出管理(1)日本への磁石輸出に大きな影響 (2026年03月10日)
- 不確実なトランプ米政権、2026年中間選挙で民主党勝利の可能性は (2025年05月20日)
- 紅海およびスエズ運河に関する物流動向 (2026年05月13日)
- 急成長を遂げる南米の新興国ガイアナ(1)石油発見で潤う国内経済 (2025年12月12日)
- ホルムズ海峡封鎖後の中東におけるエネルギー動向 (2026年06月19日)
- 米国の鉄鋼・アルミ・銅の232条関税の制度変更と企業の実務対応 (2026年05月20日)
- 中東向けの新たな物流ルートとして整備が進むオマーンの港湾 (2025年12月26日)
- 2025年度 第24回 日本企業の海外事業展開に関するアンケート調査(2026年3月)
- EU循環型経済関連法の最新概要‐エコデザイン規則(ESPR)、修理する権利指令(R2R 指令)、包装・包装廃棄物規則(PPWR)案‐(2024年11月)






